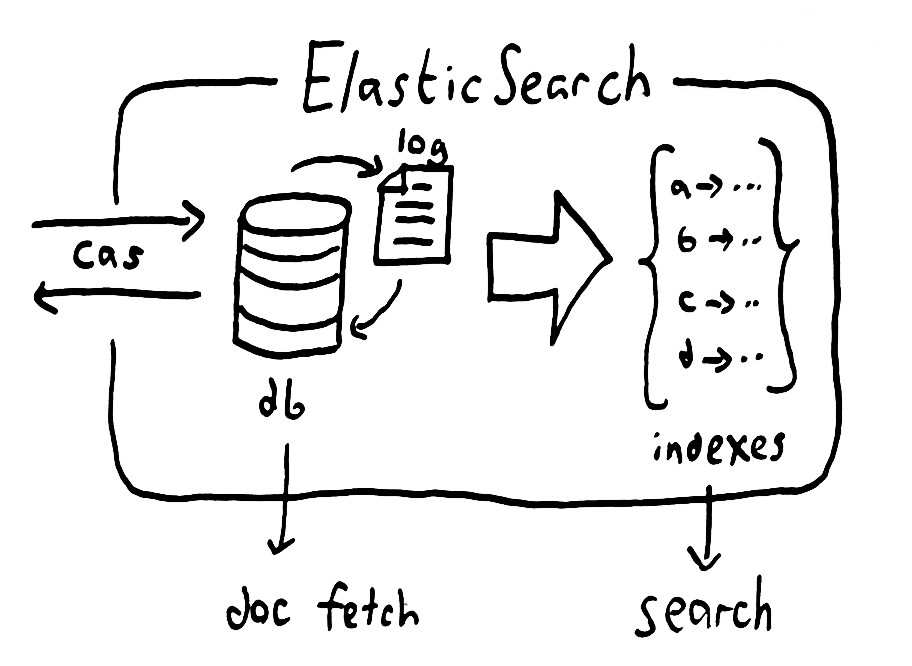
by Ola Ajibode | Dec 14, 2016 | BigData, Elasticsearch, JavaScript, NodeJS
Often you think of a solution to a simple problem and once you come up with that solution you realise you need to apply this to a large dataset. In this post, I will explain how I deployed a simple solution to a larger dataset while preparing the system for future growth. Here’s the state of play before changes in my client’s eCommerce system:
Existing System:
- Login to aggregator’s portal to retrieve datafeed URI
- Login to customer admin interface to create or update merchant details
- Create cron job to pull data from partner URI after inital setup
- Cron job dumps data in MySQL
- Client shopping UI presents search field and filters to customers to search and use
- Search result is extremely slow (homepage: 2.03 s, search results page:35.73 s, product page:28.68 s ). Notice the search results and product pages are completely unacceptable
Proposed System:
Phase 1:
- Follow steps 1-4 of existing system
- Export MySQL data as csv
- Create an instance of Elasticsearch with an index to store product data
- Export MySQL data as CSV
- Create script that bulk insert the exported data into Elasticsearch
- On command line, search Elasticsearch instance using various product attributes (product name, type, category, size etc.). Check the time speed of search results.
Phase 2:
- Build a search interface that uses Elasticsearch
- Display search results with pagination
- Add filters to search results
- AB Test existing search interface and Elasticsearch based and compare conversion (actual sales)
- Switch on the best solution – Elasticsearch
A few libraries already exists that can solve some of these challenges e.g
- Elasticsearch-CSV – https://www.npmjs.com/package/elasticsearch-csv
- SearchKit – https://github.com/searchkit/searchkit
- PingDom – https://tools.pingdom.com
In the next post, I will dive deep into how I used Elasticsearch-CSV to quickly ingest merchant data and the response I got
by Ola Ajibode | Jul 16, 2016 | Elasticsearch, General
By running a custom-built Elasticsearch on AWS, you have to do everything on the console. AWS has its Elasticsearch offering but I had this project handed over to me and it’s running an old instance of Elasticsearch before AWS had its own.
Data pollution is a common problem and you have to know exactly what to do to ensure effective cleansing of such data when it happens. So, I had a case of polluted data that if not treated will put my client in a very bad state – such that the customers can sue my client. First and foremost, the data pollution was not my fault. With that out of the way, I had to trace the journey of the data to identify the source of the pollution. Let me describe the system a bit, so you get the picture. The infrastructure has 4 main components. The first component is a system that generates CSV files based on user searches. The second component inserts each user search field value in a database(sort of). The third component picks up the generated CSV files, populates an instance of Elasticsearch and deletes the CSV file after 3 hours in which case 2 other new files have been added to the CSV repository.
# # Elasticsearch Monitoring
# Cluster Health
# Green: excellent
# Yellow: one replica is missing
# Red: at least one primary shard is down
curl -X GET http://localhost:9200/_cluster/health | python -m json.tool
curl -X GET http://${ip_address}:9200/_cluster/health | python -m json.tool
# Specific Cluster Health
curl -XGET http://localhost:9200/_cluster/health?level=indices | python -m json.tool
# Check Status via colours - green, yellow, red
curl -XGET http://localhost:9200/_cluster/health?wait_for_status=green | python -m json.tool
# Shard level
curl -XGET http://localhost:9200/_cluster/health?level=shards | python -m json.tool
curl -XGET http://localhost:9200/_all/_stats | python -m json.tool
# Bikes
curl -XGET http://localhost:9200/bike_deals/_stats | python -m json.tool
# Cars
curl -XGET http://localhost:9200/car_deals/_stats | python -m json.tool
# Multiple indices check
curl -XGET http://localhost:9200/bike_deals,car_deals/_stats | python -m json.tool
# Check Nodes
curl -XGET http://localhost:9200/_nodes/_stats | python -m json.tool
# DELETE all deals on specific index on Elastic
curl -XDELETE 'http://localhost:9200/bike_deals/?pretty=true' | python -m json.tool #powerful! Be careful!!!!
curl -XDELETE 'http://localhost:9200/bike_deals/_query' -d '{ "query" : { "match_all" : {} } }' | python -m json.tool
curl -XDELETE 'http://localhost:9200/car_deals/_query' -d '{ "query" : { "match_all" : {} } }'

by Ola Ajibode | Jan 5, 2016 | Library
Reading an article on Read an article on Oreilly.com about Software Engineers and it really resonates with me – feel free to read the article yourself. As a Software Engineer, I have discovered the miracle of self development. No company or manager can stop you if you choose the path of “continuous” self development. The world of programming used to be a mystery to me – I only discovered computers after my first degree! The question then was, how can texts and machines do so much? I remember a colleague at Shazam encouraging me to pick up a programming language. Don’t get me wrong, I was a Manual Test engineer back then and I love find bugs. It gives my great pleasure and my colleagues were aware of it. It was all manual testing until I find a bug and I had to check the server logs – for proper bug reporting – everything changes, I seem to be lost in the world of “Why is this happening?”
I took up the challenge and found a book on C (that was in early 2005!) – I was carefully advised to ignore it and go for an Object Oriented language. Java was the king then and I started studying and writing code – for real! I became excited about the fact that I could write some lines of code – hence having a better understanding of what’s happening in the backend. This greatly improved my communication of bugs to the developers. So rather than just say “the server did not return any message” it became “there was an exception thrown due to null entry on the IVR (then paste the stack trace of the exception)”. That was the start.
Since that nudged-start in 2005, I have added to my arsenal as a Software Engineer, new languages, test frameworks, web frameworks to mention but a few. So what do I need to improve in 2016?
Managing people and technology. More Cloud technologies — maybe AWS certification (to make me more serious :)), building and deploy SaaS apps with TDD, BigData plus Analytics, Leadership for engineers and I might peep into the Software Architect world. I think having a bird’s eye view of software systems might be a good thing. I will review this at the end of the year. Have a great year engineering softwares that make a difference!
by Ola Ajibode | Dec 21, 2015 | Automation, AWS, Bash, BigData, Shell, Test Automation
BigData and Agile seem not to be friendly in the past but that is no more the case. One of the important points in processes data is data integrity. Assuming you are pulling data from an API(Application Programming Interface) and performing some processing on the result before dumping as utf-8 gzipped csv files on Amazon’s S3. The task is to confirm that the files are properly encoded(UTF-8), each file has the appropriate headers, each row in each file do not have missing data and finally produce a report with filenames, column count, records count and encoding type. There are many languages today and we can use any BUT speed is of great importance. also, we want to have a Jenkins (Continuous Integration Server) job running.
I have decided to use Bash to perform these checks and will do it twice! First, I will use basic Bash commands and then will use the csvkit (http://csvkit.readthedocs.org/). The other tool in the mix is the AWS commandline tool(aws-cli)
by Ola Ajibode | Dec 3, 2015 | Automation, Bash, Shell, Test Automation
On the commandline (terminal) in the *nix world, when you need to list all the files in a directory but ignore some based on file extension e.g. pdf, sh, tsv etc. Then the command below is quite appropriate. Remember to update the list of extensions you want to ignore i.e. “sh|tsv|rb|properties”
ls -l | grep -Ev '\.(sh|tsv|rb|properties)$' | column
Let me know if this is useful.