Compare Millions of messages using Spark(PySpark)
Using the Power of Apache Spark(PySpark) to Verify Loads of Messages
Imagine a scenario where you have a system costing you about £30K to run and maintain coupled with the fact that it is a necessary component in your company’s audit trail hence it cannot deprecated just like that — as this will be an expensive business decision.
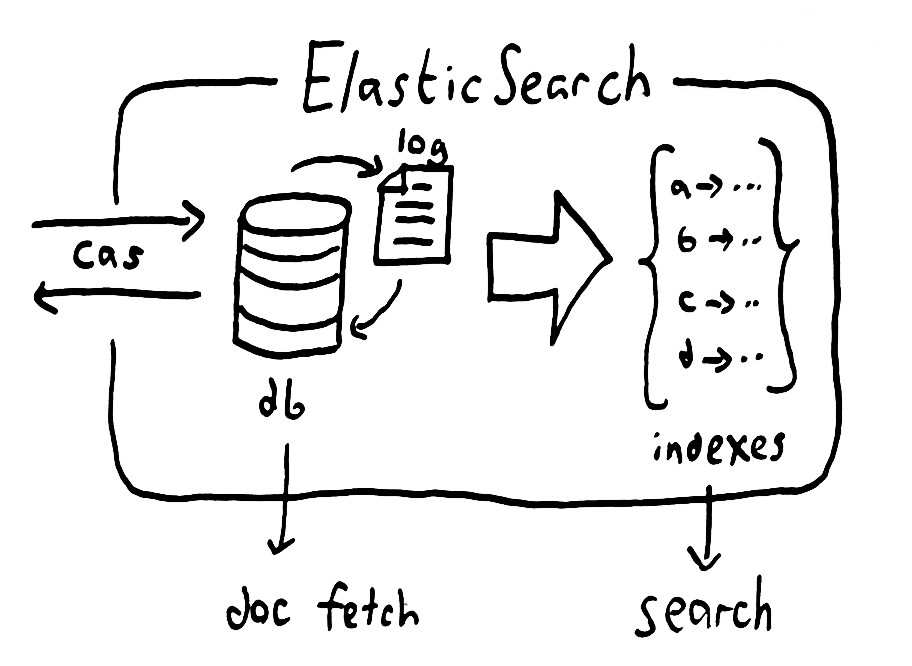
Overview of Legacy System
All events in the system emit messages for audit purposes and the messages are immediately available, for initially 7 days and then 30 days. The messages are archived once the 30 days period is achieved. Archive location of storage is simply AWS S3.
Stored messages can be retrieved from S3 as at when needed.
Various teams in the organisation need access to these audit messages and the messages are all in JSON format with the content not sorted i.e:
Message 1:
{ “username”: “bonzo”, “location”: “London”, “subject”: “mathematics”, “activityTimestamp”: “2017–02–01:21:32:00Z”}
Message 2:
{ “username”: “iyabo”, , “subject”: “english literature”, “activityTimestamp”: “2017–05–09:06:03:09Z”, “location”: “Abeokuta”}
A project to replace this legacy system has been initiated and will use Apache Kafka as a platform to produce and consume these audit events. Kafka is an open-source platform and if you stick with the free version rather than subscribe to the services provided by Confluent , the parent company, then you have to play at a lot with this beauty called Kafka. If you want to know more about Kafka, simply visit Confluent.io (don’t click away now!)
The legacy system produces audit messages in JSON format hence the new system being will use the same message protocol. The real challenge is to ensure that the new system produces exactly the same message(s) generated by the legacy system so that when legacy system is switched-off, no audit message is missing. In short, like for like system.
The key question that must be answered is this:
“Do we have all messages?”
If yes, then let’s get some messages randomly from legacy systems and confirm our new system has the exact message.
To verify massive data (BigData), you use either Stir and Compare(Sampling) or Minus queries. In simple terms, Stir and Compare, takes a sample from source data and checks if that chunk of data is present in the target data. Simple? This strategy has limitations as we are talking about big data — it won’t fit in Excel spreadsheet (over 1 Million rows!).
As for Minus Query strategy, it’s simply using machines to do the job. Run a query on source data and target data, then subtract one result-set from the other, the outcome is the set of differences between the two data sources. Please note the queries may be in different query languages (SQL/HQL — data people you understand).
Back to the task.
You can go about setting up complex tools and running scripts and any other thing that makes you feel you’re using technology to solve the problem.
Hold on, there’s a simple solution: Apache Spark. You can checkout a quick overview and quick start on Spark here and the PySpark flavour can be found here.
Let’s assume you’re up and running with PySpark, then you need to load the data you need to compare. Let’s call the 2 sets of data, primary and secondary. Primary being the source data(legacy) and Secondary the new source of data.
In Spark, we use RDD(Resilient Distributed Datasets) to hold the data and in this case I will use rdd1 and rdd2.