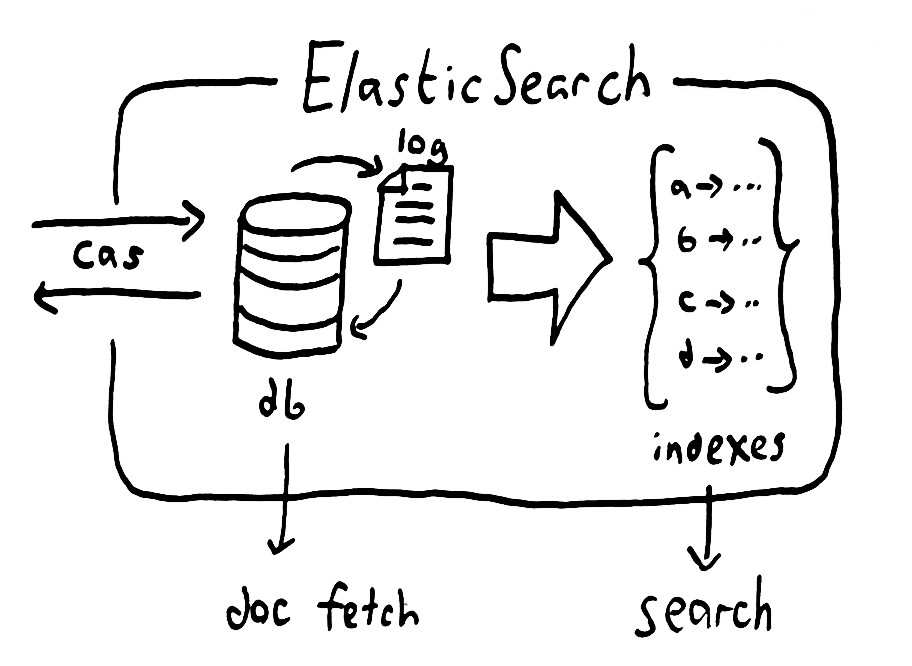
by Ola Ajibode | Dec 14, 2016 | BigData, Elasticsearch, JavaScript, NodeJS
Often you think of a solution to a simple problem and once you come up with that solution you realise you need to apply this to a large dataset. In this post, I will explain how I deployed a simple solution to a larger dataset while preparing the system for future growth. Here’s the state of play before changes in my client’s eCommerce system:
Existing System:
- Login to aggregator’s portal to retrieve datafeed URI
- Login to customer admin interface to create or update merchant details
- Create cron job to pull data from partner URI after inital setup
- Cron job dumps data in MySQL
- Client shopping UI presents search field and filters to customers to search and use
- Search result is extremely slow (homepage: 2.03 s, search results page:35.73 s, product page:28.68 s ). Notice the search results and product pages are completely unacceptable
Proposed System:
Phase 1:
- Follow steps 1-4 of existing system
- Export MySQL data as csv
- Create an instance of Elasticsearch with an index to store product data
- Export MySQL data as CSV
- Create script that bulk insert the exported data into Elasticsearch
- On command line, search Elasticsearch instance using various product attributes (product name, type, category, size etc.). Check the time speed of search results.
Phase 2:
- Build a search interface that uses Elasticsearch
- Display search results with pagination
- Add filters to search results
- AB Test existing search interface and Elasticsearch based and compare conversion (actual sales)
- Switch on the best solution – Elasticsearch
A few libraries already exists that can solve some of these challenges e.g
- Elasticsearch-CSV – https://www.npmjs.com/package/elasticsearch-csv
- SearchKit – https://github.com/searchkit/searchkit
- PingDom – https://tools.pingdom.com
In the next post, I will dive deep into how I used Elasticsearch-CSV to quickly ingest merchant data and the response I got
by Ola Ajibode | Jul 16, 2016 | Elasticsearch, General
By running a custom-built Elasticsearch on AWS, you have to do everything on the console. AWS has its Elasticsearch offering but I had this project handed over to me and it’s running an old instance of Elasticsearch before AWS had its own.
Data pollution is a common problem and you have to know exactly what to do to ensure effective cleansing of such data when it happens. So, I had a case of polluted data that if not treated will put my client in a very bad state – such that the customers can sue my client. First and foremost, the data pollution was not my fault. With that out of the way, I had to trace the journey of the data to identify the source of the pollution. Let me describe the system a bit, so you get the picture. The infrastructure has 4 main components. The first component is a system that generates CSV files based on user searches. The second component inserts each user search field value in a database(sort of). The third component picks up the generated CSV files, populates an instance of Elasticsearch and deletes the CSV file after 3 hours in which case 2 other new files have been added to the CSV repository.
# # Elasticsearch Monitoring
# Cluster Health
# Green: excellent
# Yellow: one replica is missing
# Red: at least one primary shard is down
curl -X GET http://localhost:9200/_cluster/health | python -m json.tool
curl -X GET http://${ip_address}:9200/_cluster/health | python -m json.tool
# Specific Cluster Health
curl -XGET http://localhost:9200/_cluster/health?level=indices | python -m json.tool
# Check Status via colours - green, yellow, red
curl -XGET http://localhost:9200/_cluster/health?wait_for_status=green | python -m json.tool
# Shard level
curl -XGET http://localhost:9200/_cluster/health?level=shards | python -m json.tool
curl -XGET http://localhost:9200/_all/_stats | python -m json.tool
# Bikes
curl -XGET http://localhost:9200/bike_deals/_stats | python -m json.tool
# Cars
curl -XGET http://localhost:9200/car_deals/_stats | python -m json.tool
# Multiple indices check
curl -XGET http://localhost:9200/bike_deals,car_deals/_stats | python -m json.tool
# Check Nodes
curl -XGET http://localhost:9200/_nodes/_stats | python -m json.tool
# DELETE all deals on specific index on Elastic
curl -XDELETE 'http://localhost:9200/bike_deals/?pretty=true' | python -m json.tool #powerful! Be careful!!!!
curl -XDELETE 'http://localhost:9200/bike_deals/_query' -d '{ "query" : { "match_all" : {} } }' | python -m json.tool
curl -XDELETE 'http://localhost:9200/car_deals/_query' -d '{ "query" : { "match_all" : {} } }'